
PHPのスクレイピングライブラリ「PHP Simple HTML DOM Parser」を使って、とあるサイトのランキングデータからキーワード情報をスクレイピングした方法をご紹介したいと思います。
composerでPHPに「PHP Simple HTML DOM Parser」のライブラリを設定して、SimpleHtmlDomクラスを使ってデータを取るところも説明していますので、PHPスクレイピングで情報解析をお考えの方は参考にしてください。
スクレイピングによる過度のデータ搾取や二次利用は法的問題もありますので、事前に十分配慮をしたうえで実行下さい。
APIの仕様変更
先日、「ECキーワードランキング」という、Yahooの商品検索APIのデータを使って、ECキーワードのランキングを公開していたサイトで、APIからデータが取れなくなっていたとご紹介していました。
取得できなくなったランクデータ代替案
Yahoo APIの仕様変更に伴い、これまで取得ができていた人気ECキーワードのランキングデータが取れなくなっていたことが原因ですが、これに代わるデータが何かないかを探したところ、通販サイトに検索キーワードのランキングが公開されているのをたまたま見つけましたので、このデータを使って代用できないかを試みることにしました。
スクレイピング
WEBからデータを収集するという点ではGoogleなどの検索エンジンが行っているクローリングと似ていますが、スクレイピングはWebサイトから必要なデータだけ取得して、そのデータをDBに格納して分析とかに使ってしまおうというWeb技術のため、似ているようで微妙に違うともいえます。
PHPでスクレイピング
「PHP スクレイピング」で調べると、某会社さんの技術系ブログでphpQueryの記事がでている影響もあり、phpQueryを使った説明ばかりがNETに見つかりましたが、こちらのブログを見ると、10年以上前に開発が止まったphpQueryライブラリを使うよりも、今もバージョンアップが続けられている「PHP Simple HTML DOM Parser」を使う方が賢明だというご意見もありましたので、「PHP Simple HTML DOM Parser」を使って今回はやってみることにしました。
PHPのスクレイピングのライブラリは「PHP Simple HTML DOM Parser」がオススメ
PHPでスクレイピング。phpQueryとphp-simple-html-dom-parserの比較と設置方法 | エス技研
composerによるSimple HTML DOM Parser追加
エス技研さんの記事では、Simple HTML DOM Parserの利用にあたっては、ダウンロードしてFTPを上げて設定すると書いてありましたが、twitter系APIの「cowitter」を設定したときにも使った「composer」が私にはありますので、このcomposerを使って設定をしてみました。
% php composer.phar require simplehtmldom/simplehtmldomライブラリも見つかったのでパパっと行けるかと思いきや、composerがエラーを吐いてうまく動いてくれません。エラーを見ると、どうやら安定バージョンが見つからないと怒られているようです。
[InvalidArgumentException]
Could not find a version of package simplehtmldom/simplehtmldom matching your minimum-stability (stable).色々調べてみると、リリースバージョンをお尻に付けて叩けばインストールできるよ。という謎の海外ブログを見つけたので、その通りにやってみたらうまくいきました。
% php composer.phar require simplehtmldom/simplehtmldom:2.0-RC2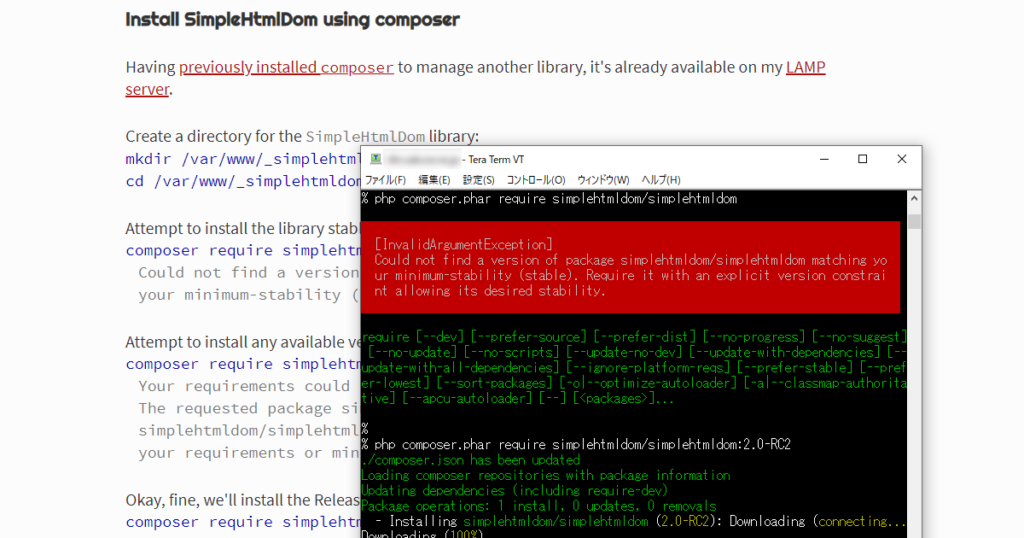
Simple HTML DOM Parserの利用
ライブラリのインストールができましたので、早速使ってみます。simple_html_dom.phpというファイルがどこかに生成されているので、まずはこれを読み込みます。
require '/simplehtmldom/simplehtmldom/simple_html_dom.php';このsimple_html_dom.phpの中身をみてみると、HTMLファイル全体を取り込むfunction file_get_html()と、HTMLファイルから指定文字列を使って取り込むfunction str_get_html()の2つが用意されているようですが、とりあえずfunction file_get_html()を使ってターゲットとするURLの内容を取り込んでみます。
$html = file_get_html($Target_URL);すると、関数内で対象ファイルを読み込んだsimple_html_domクラスのインスタンスをnewしてくれるようなので、あとはこの$htmlを操作すれば大丈夫そうです。
取り込んだ$htmlの中身を見てもらえれば、データが確認できると思いますので、例えば、<a>タグのhref属性だけを取り出したいということであれば、下記のような感じで呼び出してあげれば、$html内のリンクを全て集めることがができます。簡単ですね。
//a要素取得
foreach($html->find('a') as $element){
echo $element->href;
}スクレイピングしたデータ
私が欲しかったものは人気度順となったEC関連キーワードでしたが、取得したランキングページの<a>タグhref属性内に、エンコードされたキーワード文字列が入っていましたので、このエンコード部分を引っ張り出して、デコードしてあげれば欲しいデータを手に入れることができました。
https://search.***.**.jp/search/mall/%E3%83%9E%E3%82%B9%E3%82%AF/
取得できた楽天市場の商品キーワードリンク
上記のようなキーワード入りURLからキーワード文字列を取得するコードサンプルです。
URLの最後尾/を取ってから/で区切り、最後尾要素だけ取り出してデコードしてキーワードを配列に放り投げるといった雑な感じですが、これでなんとかなりました。
foreach($html->find('a') as $element){
$KeyWord[] = urldecode(end(explode("/",substr($element->href, 0, -1))));
}おわりに
APIで取得していたデータには、検索スコアや関連キーワードといったデータも付与されておりましたので、若干データ量は少なくなってしまいましたが、EC関連キーワードの定量的なランキングを取得することができるようになりました。
APIサービスの終了で、機能的にはこのサイトも終わりかと思いましたが、これで継続させることができました。サイト名も「Keyword Tool++」と新たに変えて引き続き運営していきたいと思います。