
ツイッターのトレンド情報を取得できるTwitter API(GET trends/place API)を使ってトレンドキーワードをひたすら収集し、集めたキーワードを月別のランキングとしたサイト「ツイータン」を運営しています。
2019年末からスタートして、2020年は丸一年間運営をすることができましたので、2020年一年間で集めたトレンドの#ハッシュタグ、キーワードを年間ランキングにしてみました。
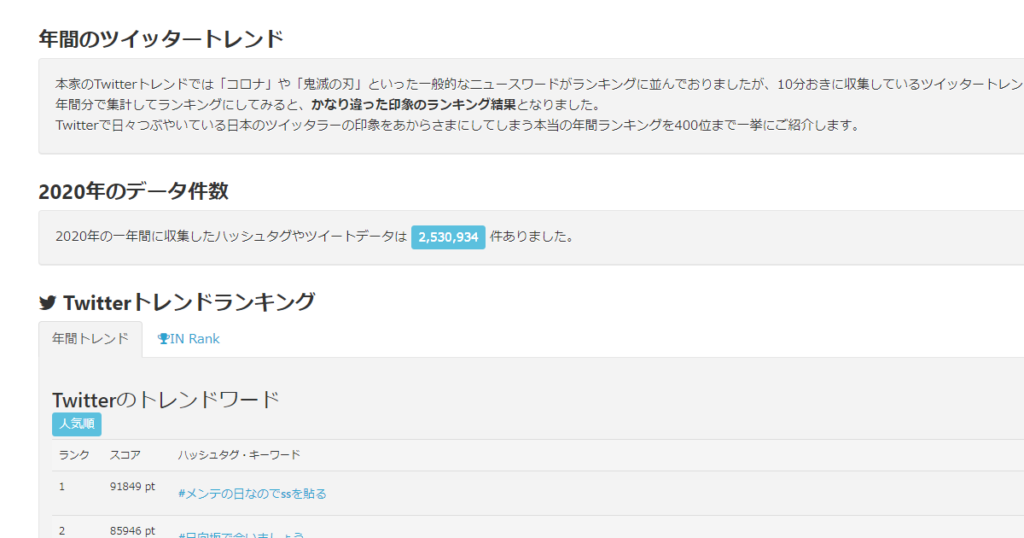
本日時点で2,530,934レコードのトレンド#ハッシュタグ、トレンドキーワードを、上位400位まで一覧のランキングとした、2020年間Twitterトレンドワードランキングをご用意してあります。是非ご確認下さい。
この記事では、その2020年間Twitterトレンドランキングの集計方法や、Twitter公式の年間ランキングや大手のトレンドワードランキングとの違いを検証した内容をご紹介しております。
Twitter APIのトレンドデータ
ツイッターのトレンド情報を取得できるTwitter GET trends/place APIを使い「tweetan」というサイトを作ってありますが、2020年も大晦日となりましたので、10分毎に収集するトレンドデータの一年分を使ってランキングを抽出してみることにしました。
Twitter APIのデータ取得方法
Twitter APIからのデータ取得方法の基本については、PHPのcowitterライブラリを使ってデータ取得をする手順を説明しているこちらの記事をご参照ください。
GET trends/place APIの仕様
Twitterで盛り上がっているツイート・ハッシュタグをリアルタイムで取得することができる、Twitter GET trends/place APIの仕様や使い方については、こちらの記事でご紹介しています。
年間で収集したデータ件数
API側では5分毎にトレンドデータが更新されるようですので、当初は5分おきにデータ取得をかけていましたが、サーバ負荷も考えて10分おきのバッチ処理に変更をしておりました。
一度に取得可能なトレンドランキングデータは50件程度なので、これで単純計算すると日に7,200レコード、365日で2,628,000レコードが取得される予定でしたが、実際には今日の時点では2,530,934レコードとなっていたので、50レコードを取れなかったことが結構あったのかもしれません。
とはいえ、これだけデータがたまっていれば年間トレンドの集計をするのにも問題はなさそうです。
ログデータから2020年分を抽出
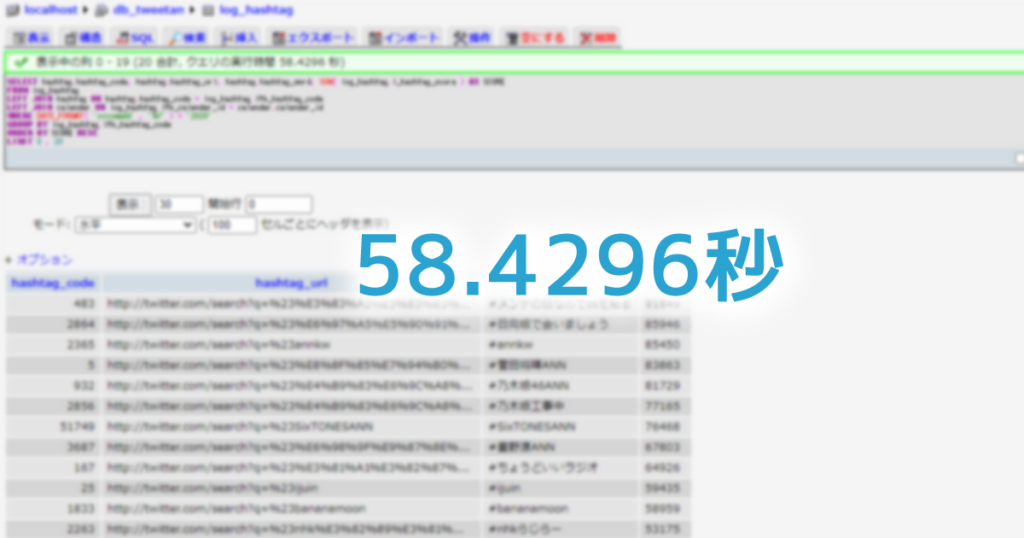
ログデータをためるトランテーブルを見ると320万レコード程たまっているので、ここから2020年分データを切り出しつつ、レコードに保持をさせたランキングスコアでSUM ORDER BYをしてみました。
上位20件程度を試しに抽出してみたところ、実行時間が58.4296秒もかかってしまい、とてもプログラムにかませるといったことができなさそうでした。
抽出データで静的ページを作成
月次のランキングのように毎月定期出力するというものでもないので、とりあえずSQLで取得したデータを使って静的ページを作ってしまうことにしました。完成したものがこちらの2020 Twitter 年間トレンドランキングとなります。
大手のランキング結果とだいぶ異なる
ランキングの結果を某社がやっているTwitter年間トレンドと比べてもらうと一目瞭然でしょうが、ランキングのトレンドワードが全く違う印象のものとなってしまっておりました。
こちらは毎月おなじみの「メンテの日なのでssを貼る」や「日向坂で会いましょう」がランキング上位に並んでおりますが、あちらのランキングだと「ニュースワードランキング」といった印象のワードばかりが並んでおりました。世の中のトレンドという意味では大手の年間ランキングの方がしっくりくる感じです。
1位 コロナ(新型コロナ)
大手の年間トレンドランキング
2位 #検察庁法改正案に抗議します
3位 緊急事態宣言
4位 100日後に死ぬワニ
5位 鬼滅の刃
1位 #メンテの日なのでssを貼る
tweetanの年間トレンドランキング
2位 #日向坂で会いましょう
3位 #annkw
4位 #菅田将暉ANN
5位 #乃木坂46ANN
6位 #乃木坂工事中
7位 #SixTONESANN
8位 #星野源ANN
違いの原因はAPIのtweet_volumeの値
以前の記事でもご紹介していますが、Twitter GET trends/place APIのJSONレスポンスデータにはツイートボリュームもあることはありますが、ほとんどがNULLデータばかりとなってしまっており、肝心のツイートボリュームをまともに取得することができませんでした。
[
{
"trends": [
{
"name": "あなたの精神年齢",
"url": "http://twitter.com/search?q=%E3%81%82%E3%81%AA%E3%81%9F%E3%81%AE%E7%B2%BE%E7%A5%9E%E5%B9%B4%E9%BD%A2",
"promoted_content": null,
"query": "%E3%81%82%E3%81%AA%E3%81%9F%E3%81%AE%E7%B2%BE%E7%A5%9E%E5%B9%B4%E9%BD%A2",
"tweet_volume": null
},ランキングの順位でスコアリング
tweet_volumeの値が取れなかったため、「1位:50点」~「50位:1点」まで単純にスコアリングをするしかできず、大手ランキングで1位の「コロナ(新型コロナ)」というワードが瞬間的に100万ツイートされていても、同じく夜中に「#メンテの日なのでssを貼る」でトレンド1位になったものと同じ扱いとなってしまうこととなり、このあたりが原因かとは考えておりました。
大手ワードをTwitter APIのログで見る
とはいえ、一年間ひたすら取得した320万レコードのTwitter GET trends/place APIのレスポンスデータで大手ランキングで1位の「コロナ(新型コロナ)」というワードを見てみると、少々気になるところがありました。
大手ワードのトレンド入り回数が異様に少ない
保有するログデータで「新型コロナ」を調べてみると、トレンドに入ったのは4月中旬に6回しかなく、「コロナ」の方は2月下旬にたった2回しかありませんでした。
気になったので他のワードについても見てみましたが、「緊急事態宣言」は562回とある程度ログにも入っていましたが、「100日後に死ぬワニ」についてはログに一度も入っておらず、10万語以上あるツイート、ハッシュタグのマスターデータの中に存在すらしていませんでした。
Twitterトレンドはどのように決定されるか
Twitterのヘルプセンターにも記載がありますが、Twitterトレンドというものはこのような仕組みでアルゴリズムされているようです。
トレンドはアルゴリズムによって決定され、….ここ数日や今日1日で話題になったトピックではなく、今まさに注目されているトピックが選び出されるため、Twitterで盛り上がっている最新の話題をリアルタイムで見つけることができます。
Twitterのヘルプセンター
じわじわとツイートされていたものの、Twitterで盛り上がるといったことがなかったため、Twitterトレンドにはならなかったということなのかもしれないですが、「#乃木坂工事中」ハッシュタグですら2,197回はトレンドログに出現しているので、本当にみんながツイートして盛り上がっていたものをランキングにしたのか?といったことが少々気にはなってしまいます。
大手サイトのランキング説明
某大手ランキングの説明を見ると、「Twitterのトレンドにランクインしたワードを様々なデータ*から検証」とあり、※注釈には「*ツイート数・トレンド欄のワードクリック数/露出回数など」といったことも補足で書いてありました。
単純にTwitterのトレンドデータだけということではないようですので、「100日後に死ぬワニ」はツイート数は少なくてもインプレッションは恐ろしくあったということで、年間ランク4位というランキングになったということなのかもしれませんが、そもそものTwitterのトレンドの仕様とはだいぶ異なるようですので、なんだか違和感が残ります。
おわりに
Twitterの年間トレンドランキングという名前は同じですが、元とするデータと指標や抽出方法も全く違うため、全く別物のランキングということのようです。
どちらかというとtweetanのランキングの方が、Twitterで普段つぶやく人のイメージに合っているような気がしてしまいますが、色々見比べると面白いことが分かったような気がしました。